
发布时间 : 2020-11-09 阅读量 : 1232
openslr 中国镜像背后的数据存储服务商,原来是这样一家公司!

作者 | 夕颜 采访嘉宾 | 张晴晴 出品 | csdn(id:csdnnews)
从事语音领域的开发者、学习者一定对openslr不陌生,这个美国著名的语音资源开放平台托管着来自世界各地的开源语音数据资源。在语音识别开源工具kaldi创始人daniel povey的参与促成下,openslr中国镜像让中国的开发者能够享受到更多福利。通过这个镜像,中国开发者就可以更加便捷地下载openslr 的开源数据。
而为这个镜像提供数据存储服务的厂商是一家名为magic data的中国企业,daniel本人还担任这家公司的语音顾问。
这不禁让人好奇,这是一家怎样的企业?捋清楚这家公司的发展脉络后,会发现这家兴起于国内ai与数据浪潮兴起之时的数据厂商,其四年的发展历程,俨然是中国数据服务从粗放模式到精细化运营转变的缩影。
大数据浪尖弄潮,见证国内 ai 数据服务行业变迁
magic data的创立者是法国“海归”博士后语音专家张晴晴。
初识语音,起于张晴晴在大三时期接触到《语音信号数字处理》(作者:杨行峻,迟惠生)这本书。当时,这门课由大唐电信的专家担任教授,大四选择报送学校时,张晴晴意识到自己对中科院声学所的语音课程很感兴趣,当时还请教授为她写了一份参考名单。从此,她便与语音结下不解之缘。
2010年,张晴晴获得了在法国国家实验室limsi-cnrs读语音信号处理博士后的机会,研究课题是大词汇连续语音识别的声学建模。在这里,她有机会参与欧盟的一个项目,涉及欧洲多语种语音的识别。这一年,她最大的收获,是可以在国际范围内评判最好的数据处理方法和算法,这支团队注重公允和严谨的作风,也对她日后的专业研究产生了重要的影响。
2011年,张晴晴从limsi-cnrs学成归国,来到中国科学院声学研究所,从事大词汇连续语音识别的声学建模以及语言建模研究工作。
在中科院的日子让张晴晴加深了人工智能对数据依赖性的深入认识和理解,创立一家专业的数据服务公司,为客户提供更专业数据的想法开始萌芽。之后数年,在数据行业的经历加深了她对数据重要性的认识,做业内最好的数据服务公司的想法越来越强烈。
张晴晴回忆,在研究生和博士期间,为了做声学模型和语言模型的搭建及算法,张晴晴购买过一些数据用于模型训练,然而在这个过程中,她发现传统的数据提供商做出来的数据用起来并不顺手,有些数据的处理方式也并不是她想要的。在那个时候,其实大家都知道数据对于人工智能的重要性,数据质量跟不上的情况下模型的训练就是“garbage in,garbage out”,但是没有多少人愿意静下心来做数据。可没有好的数据,就无法提高产品的性能。
“我意识到,好的数据处理方式,能够给最后的识别性能带来可观的性能提升。为了了解各行业数据的基本情况,我离开声学所,去到企业中去,期间了解到各企业的数据的采集及处理方法,但是从科研角度来说,这些方法还是有一定的缺陷,”她说。
在人工智能发展处于低谷时期时,张晴晴做过很多研究算法工作,当时gpu、大数据还没有被广泛使用,大部分人还未意识到数据的重要性。而从2016 年左右起,国内 ai 和大数据热潮涌起,相关硬件和软件开始被大规模使用,拥有数据的企业和能够高效处理数据的企业的核心的价值和与能力才逐渐凸显出来,各种数据服务公司如雨后春笋破土而出,鱼龙混杂。
亲历人工智能变迁的过程,深刻理解数据和算法的价值和不足,张晴晴深谙这个领域是一片大有可为的“蓝海”。张晴晴做出一个重大决定,离开声学所,自立门户,创办了一家数据服务公司——magic data,为语音识别、语音合成、自然语言处理、计算机视觉领域提供数据采集和标注服务。
没过多久,乘着ai和数据行业吹起来的“东风”,magic data也在变化中迎来了全新的发展契机。
首先,2020 年,与公司创立之初相比,张晴晴感觉到了 ai 数据服务行业已然发生了非常明显的变化。
2010 年左右,人工智能改变了算法,从过去的浅层学习转向了深度学习。与此同时,智能硬件的流行使得对数据的需求突飞猛进式的增长,如果依靠传统数据公司纯人工的数据处理方法,数据质量和效率都无法满足精准化数据的需求。另外,做模型研究与应用的人也逐渐认识到,数据质量与识别性能相比的重要性只多不少,数据处理方式的优化更是比算法优化更重要。
张晴晴分析道,从行业发展来说,越来越多的企业开始利用收集来的数据构建部署 ai 模型,以支持新服务,也有越来越多的企业将倚重 ai 来提高员工生产力。人工智能行业仍以有监督学习的模型训练方式为主,对于标注数据有着强依赖性需求。
其次,从本质上来说,数据就像是“草料”,只有数据有营养,才能让机器学习这匹马“跑”起来。然而,在实际行业应用场景中,数据服务还是面临着一些痛点。
比如张晴晴最为熟悉的语音识别领域,有限词汇是语音识别中的一个难点,虽然当前语音识别技术已经能够识别出大部分的英语单词,但是在识别人名和俚语上仍然有困难,如何降低有限词汇(out of vocabulary)对识别率的影响,magic data研发了具有自主知识产权的发音词典标注系统。在这套系统中,机器可以基于现有的词典,对新词的发音进行预测,并将结果反馈给标注员,以便标注员可以更快地进行标注,并将此发音加入到词典中。通过这样的方式,magic data可以快速地对词典进行更新迭代,从而加快 oov 问题的解决。
此外,语音识别模型需要大量的数据来学习新单词,magic data为各种语言提供了大规模的发音词典和相应的语音数据集,并设计了多种语料库。
再比如,ai 系统具有偏见而造成的一系列问题越来越严重,以最典型的人脸识别大厂微软、ibm、facebook为例,三者的人脸识别系统均被证明识别白人的准确率高于肤色较深的人种,因此引起很多争议。针对ai系统偏见,企业和开发者们也都给出了一些凯发体育网的解决方案,但是归根结底,从最底层的数据层面保证数据的“中立”,是杜绝 ai 偏见最简单、有效的途径。而怎样保持数据无偏见,也是行业内一个艰难的挑战。
“模型的偏见来自于有偏见的数据。我们会针对应用场景给出全方位的数据凯发体育网的解决方案。我们会根据客户的应用场景,结合客户目前的数据情况状态,针对性的给他们设计应用场景的语料,提高数据的覆盖范围,以及该场景下的发音特点。与我们的常识相悖的是,对模型来说,纯粹干净(比如没有背景噪声)的数据不一定是好的。因为真实场景下的语音识别十分复杂,比如环境可能是有噪音的,说话人口音多样等。因此,数据的采集环境一定要尽可能的接近真实环境。”张晴晴说。
从张晴晴的描述来看,ai数据服务行业正在经历着一场变革,ai商业化进程的演进已经使得传统的数据服务方式滞后,无法满足日益多样化的数据服务需求。
ai 数据服务行业变化丛生,爱数一站式服务解决产业痛点
在这样的环境下,行业实践证明,更具有前瞻性的数据集产品和高定制化服务成为了ai基础数据服务行业的主要服务形式。张晴晴认为,从行业内部来看,伴随着上一轮 ai 创业热潮的平息,行业经过了一轮洗牌,在业务能力、品牌效益、服务意识、资质等方面均有优势经验的品牌商地位逐渐凸显。
为适应这样的需求变化,magic data的数据服务产品不断更新迭代,形成了现在的一站式数据服务。
目前,magic data提供一站式的数据服务,包括数据采集、清洗、处理、转写标注、文本理解、图像标注,以及多模态服务。ai应用对于场景变化非常敏感,因此,为适应不同场景下的数据要求,magic data提供定制化数据,也就是一站式数据服务,在与客户沟通了解要求之后,制定数据方案,与客户达成共识之后,再进行数据的采集、转写标注、清洗等服务,为客户提供结构化的数据。
目前,magic data拥有海量的成品数据集,支持超过50个语种,涵盖多个场景数据集,包括客服场景、社交媒体、在线教育、智能车载、智能医疗、新零售等。

在帮助企业训练ai客服或商用机器人等人工智能模型上,magic data凯发体育网址官网近期新增大量适用于语音识别和语音合成领域的方言及外语数据集,包括上海、四川、广东、郑州、武汉、湖南、山西等地方言,以及泰语、西班牙语、印尼语等外语,覆盖不同年龄性别的人群和场景的数据集。
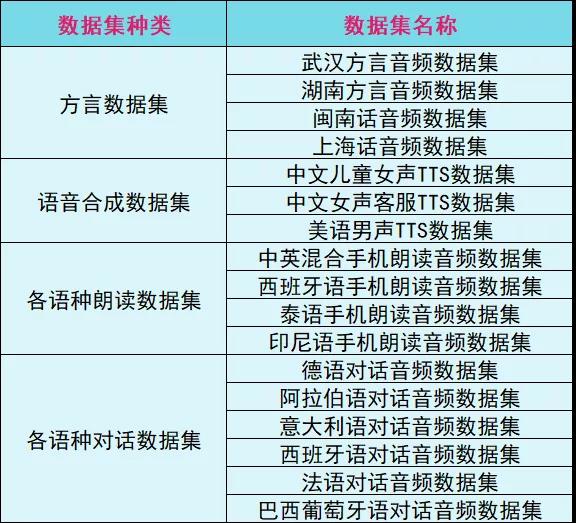
这样的数据集意义重大,因为目前来说,方言与外语语音识别与合成仍然是业内一个十分棘手的问题,很多性能表现优越的产品都会因为方言和外语识别困难,让用户的使用体验大打折扣。有了类似的数据集,才能训练出能够更好识别方言、外语的ai,在现实场景应用中才能更好地落地。
此外,现在人们在很多场景下会有中英混合的说话习惯,此类语音的识别也是语音识别领域的一大难题。magic data继续新增“中英混合手机朗读音频数据集”,方便ai企业进行多种语言混合识别产品的开发。
从技术层面上来讲,magic data数据产品的生产过程也与传统方法有所不同,比如在数据采集环节采用人机协同的方法,以行业标杆级独立知识产权设计下的录音环境,实现高标准的数据采集,提高了数据的质量和可靠性,为后续处理、清洗降低了难度和成本。通过机器筛除前期采集中的低质数据,这样可以大大减轻后期数据清洗的工作量,使数据采集精度达到99%以上,因而更好地确保数据产品的质量。
值得注意的是,数据集开源也能体现一家数据公司的实力,也能体现其开放的态度。如今,magic data已开源多个语音数据集,包括近期发布的英语发音评测数据集(14 小时中国人说英语的数据,主要是在近场环境,不存在明显混响、噪音情况下录制的朗读风格的数据),30小时的日语语料库,中文童声语音合成数据集,以及openslr上开源的包含755小时的中文朗读语音数据集等。
开源开放的态度与过硬的数据实力,造就了magic data的吸“粉”体质。
ai 与大数据时代,数据服务行业将去往何方?
ai 时代,大数据与 ai 相互促进,数据服务行业将作为 ai 制造流水线上的“操作工”,掌控着 ai 发展的进度和质量。
magic data作为国内领先的数据服务提供商,既是国内数据服务行业的参与者,也是变革者,包括其在openslr等开源平台上所做的数据集贡献。magic data近期入选《硅谷评论》“2020年度30家成长最快的科技公司”榜单,表明业内对其致力于数据推动应用创新,推动人工智能技术应用与发展的肯定。
当下,行业对数据的要求更加精准化,数据服务行业未来将会出现哪些趋势?数据服务企业该如何应对这些变化呢?在数据行业从业十多年的张晴晴给出了自己的看法。
她认为,ai 数据服务行业与行业用户将更紧密地贴合,场景更丰富,当然,竞争也会日渐激烈。为适应变化,数据服务企业应当:
具备更前瞻性的数据集产品设计能力,推出相关的技术工具; 提高对数据预处理能力,减少人力成本。
“更重要的是,利用一体化数据平台对各个环节人员行为和数据质量进行把控(多重追责性的全查、抽查机制),以确保最终产出的结构化,数据合规、保质。”张晴晴说道。