
发布时间 : 2022-12-21 阅读量 : 963
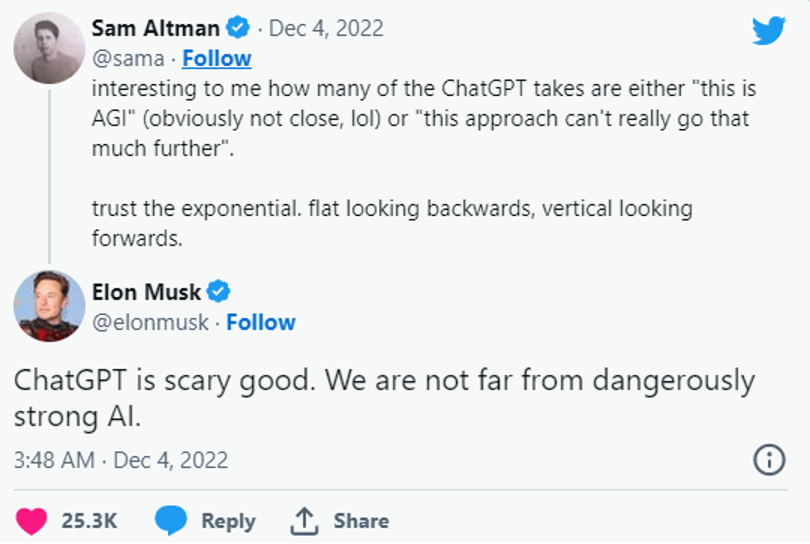
在过去的一月里,人工智能领域中最火的话题莫过"chatgpt"。chatgpt是openai于11月30日发布最新作品聊天机器人,开放公众免费测试。聊天机器人是一种软件应用程序,根据用户的提问做出回应、模仿人类的对话方式。目前,chatgpt的用户量已经超过一百万。它既能完成包括写代码,修bug(代码改错),翻译文献,写小说,写商业文案,创作菜谱,做作业,评价作业等一系列常见文字输出型任务,而且在和用户对话时,能记住对话的上下文,反应非常逼真。连马斯克都在推特上称赞道,“chatgpt真是惊人的好。我们离危险的强大人工智能不远了”:
甚至有人传言下一代gpt4可能可以取代google、百度等传统搜索引擎。让世界科技大佬都称赞的chatgpt,到底是如何对答如流的呢?
据openai报道,chatgpt模型是“从人类反馈中强化学习”(rlhf)的机器学习技术训练的。rlhf可以模拟对话,回答衍生问题,承认错误,质疑不正确的前提,并且拒绝不适当的请求。其底层结构仍然是基于自我注意力机制(self-attention)的transformer模型。该模型能够同时并行进行数据计算和模型训练,训练时长更短,并且训练得出的模型可用语法解释,也就是模型具有可解释性。
与所有大数据模型一样,chatgpt同样也是经过“预训练 微调”的过程,但是openai这次在数据收集上设置上有了细微的差别。结合人类反馈信息来训练语言模型使其能理解指令,也就是模型训练中加入了人类的评价和反馈数据,而不仅仅是事先准备好的数据集。通过公测形式可以积累大量用户反馈数据继续优化chatgpt的性能。引入“人工标注数据 强化学习“来不断fine-tune预训练语言模型,主要目的是让llm模型学会理解人类的命令指令的含义,其训练步骤分为三部:
 [来源](http:/ /)
[来源](http:/ /)
第一阶段:首先会从测试用户提交的prompt(就是指令或问题)中随机抽取一批,靠专业的标注人员,给出指定prompt的高质量答案,然后用这些人工标注好的数据来fine-tune gpt 3.5模型。第二阶段:通过人工标注训练数据,来训练回报模型。第三阶段:采用强化学习来增强预训练模型的能力。基于上述算法和训练技巧,相对以往的人机对话模型来说,chatgpt可以非常好地模拟人类的聊天行为,理解能力和交互性表现也更强,并能精准地回答用户提问,将大幅提升用户使用体验。
尽管chatgpt对大部分问答回复的都非常完美,但是,chatgpt本质上和传统的聊天机器人并没有分别——它并不理解自己所说的话,有时回答内容还是会犯一些低级错误。一段“网友调教这只ai”的聊天记录,让人不禁质疑ai是否真的鄙人聪明,对于27是质数与否为题回答有误,也表明了人工智能“智障”的一面。

chatgpt的智能是以大量对话数据的训练为基石,“智障”是由于数据不完备造成。据统计,从chatgpt进化到chatgpt-3的过程相当烧数据—参数量从1.17亿增加到1750亿,预训练数据量从5gb增加到45tb。尽管如此吃数据,仍没成长为全面人工智人。可见需要源源不断的真实场景数据的训练,才会让chatgpt越来越好。
但是对话数据的采集成本较高,需要专业的数据公司团队采集、清洗、标注。作为全球领先ai数据凯发体育网的解决方案提供商,magic data的对话式ai数据集可以为类似chatgpt的大模型提供各类垂直场景下的对话语料,帮助机器学习模型性能定向调优,拓展其特定场景下的对话式ai交互能力。
magichub数据开源社区已开源部分基于chatgpt的可扩展的对话数据集,包括:
教育客服文本数据集
样例:

金融客服文本数据集
样例:

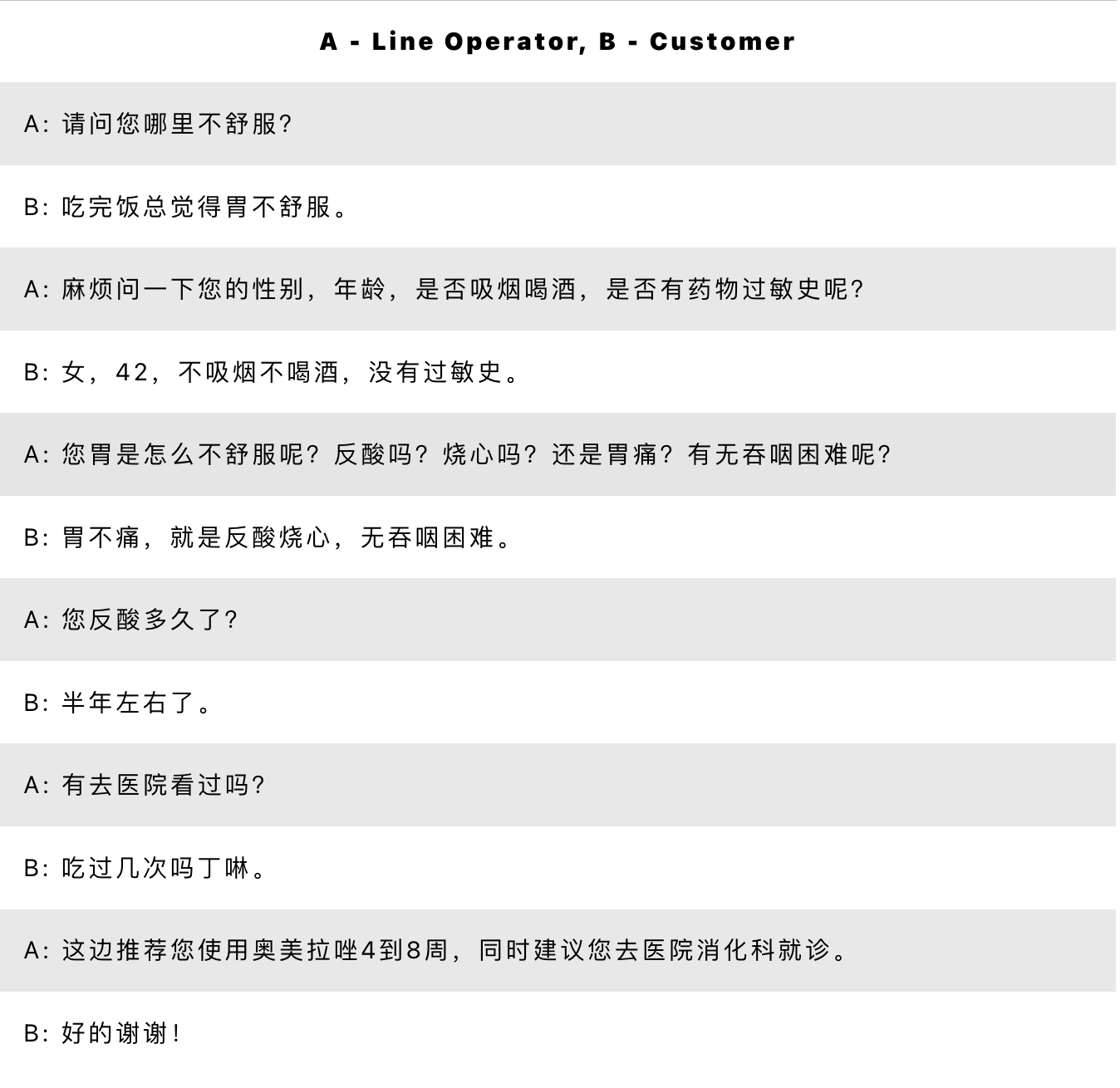
医疗客服文本数据集
样例:
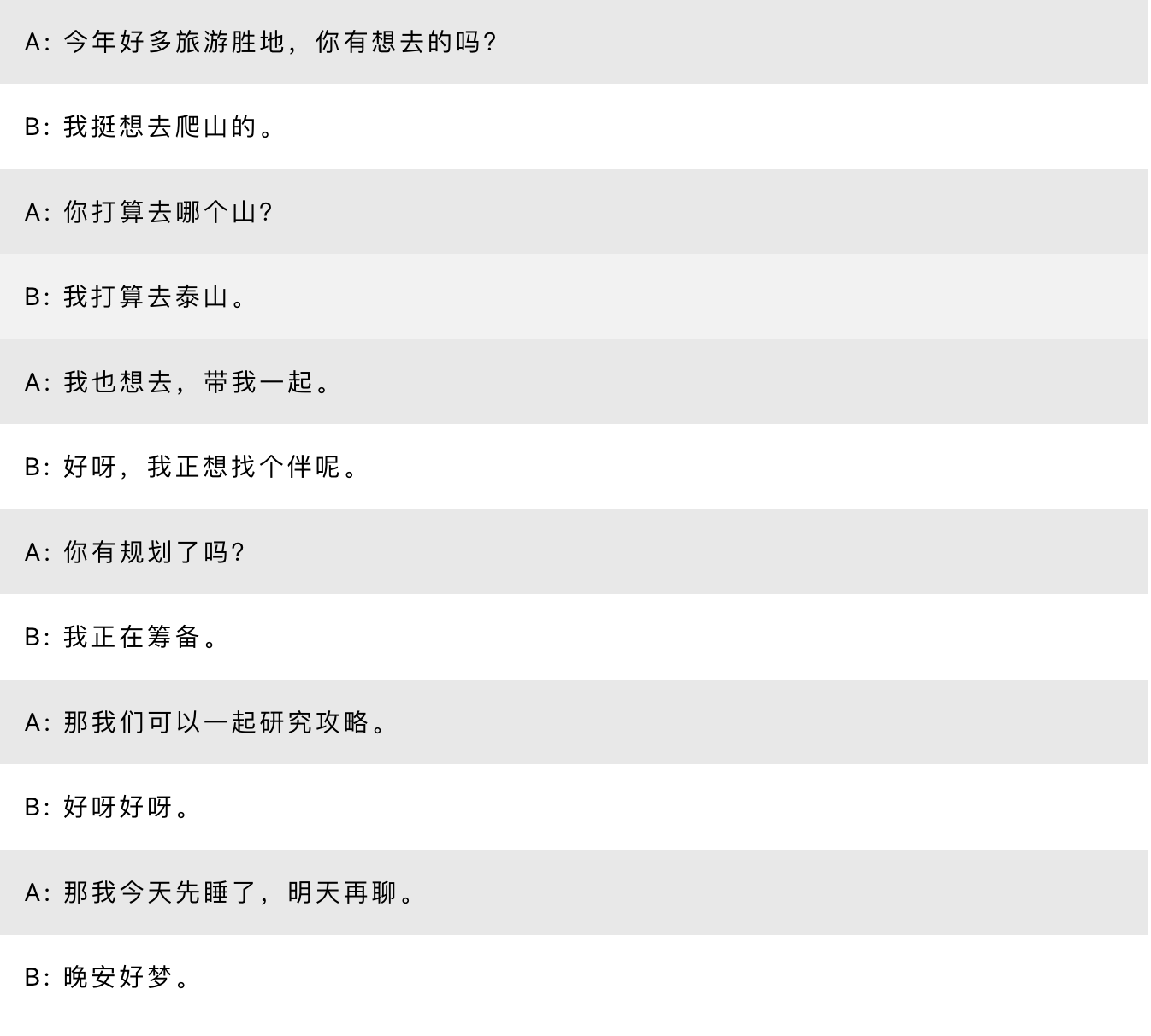
中文日常聊天文本数据集
样例:
即刻前往magichub数据开源社区,免费下载使用!
中文教育客服文本数据集
中文金融客服文本数据集
中文医疗客服文本数据集
中文日常聊天文本数据集
