
发布时间 : 2022-12-08 阅读量 : 226
近期, 自然语言处理nlp与图像方面的sota的模型基本都是基于大数据和大模型预训练pretrain的。当我们翱翔在搭积木垒大模型的时候,你可曾想过,也许我们垒的大模型,数据压根就无法完全训练好,换句话说也许你垒的大模型参数过大,高质量的数据不足,导致模型训练欠拟合。
最近,看到一篇分析高质量数据数量有限的文章,这篇文章预测了 2022 年至 2100 年间可用的图像和语言数据总量,并据此估计了未来大模型训练数据集规模的增长趋势。

来源
研究结果表明高质量的语言数据存量将在 2026 年耗尽,低质量的语言数据和图像数据的存量将分别在 2030 年至 2050 年、2030 年至 2060 年枯竭。这就意味着如果数据生产的效率没有显著提高或有新的数据源可用,那么到 2040 年,模型的规模增长将放缓,这将会是人工智能领域最大的瓶颈。
众所周知,算法、算力和数据是人工智能的三驾马车,是行业发展的基石。
人工智能的高速发展离不开ai算法持续突破创新,随着模型复杂度指数级提升,算法的不断突破创新也持续提升了算法模型的准确率和效率,各类算法方案快速发展并落地于各领域,不断衍生出新的变种,模型的持续丰富也使得场景的适应能力逐步提升。
算力是人工智能发展的技术保障,是人工智能发展的动力和引擎。目前全球 ai 算力主要是以 gpu芯片为主,随着技术的不断迭代,支撑 ai 技术发展的底层技术不断迭代,ai算法得到的算力支持越来越好。
ai算法的训练离不开数据的加持,其实网上所有的信息都可以称为数据,通俗理解,大数据就是用现有的一般技术难以管理的大量数据的集合。大数据具有有三大特征:体量大、多维度、全面性。模型训练数据的丰富程度、清洗的干净程度一定程度上决定了 ai 算法的优劣。数据是一切智慧物体的学习资源,没有了数据,任何智慧体都很难学习到知识。
如果出现数据危机,人工智能将止步不前。尤其是我们大量使用的google翻译、sari智能语音助手、数字虚拟人语音合成等技术都是依赖大量的高质量的标注数据来完成模型训练。但是,这些人工智能产品还不够完美,还需要算法精进与额外的大量的数据加持,但是上面的报道研究表明人类社会虽然无时无刻在产生数据,但是高质量数据即将枯竭。针对这个迫在眉睫的挑战,需要算法工程师和数据供应商共同努力解决。
算法工程师需要致力于研究小模型和迁移学习算法。目前大量的语言模型都是基于巨量参数的大模型,如何精准使用数据研究出又小又smart的小模型是未来发展的一个方向。此外,我们可以使用迁移学习的方法将预训练的大模型的性能,通过微调或者域自适应的算法迁移到目标小数据集上,扩展大模型的应用领域,同时减少每个应用场景的大数据需求。
算法工程师能做到的是缓解数据枯竭带来的危机,解决危机的根本方法还是生产大量、高质量的标注数据,充盈大数据仓库。数据标注是ai的上游基础产业,应该以人工标注为主,并且借助算法与机器共同标注,减少人力资本投入,提升数据生产效率。
magic data 作为全球领先的ai数据提供商,致力于通过高标准且安全合规的采集、清洗、整理、标注流程,为企业和科研机构提供高质量ai数据。

查看更多 magic data 自有数据集
同时,magic data打造智能化标注平台annotator,该平台能够标注各种场景的数据,例如车载、家居、室外等各种场景,标注效率和质量获得海内外众多客户肯定。
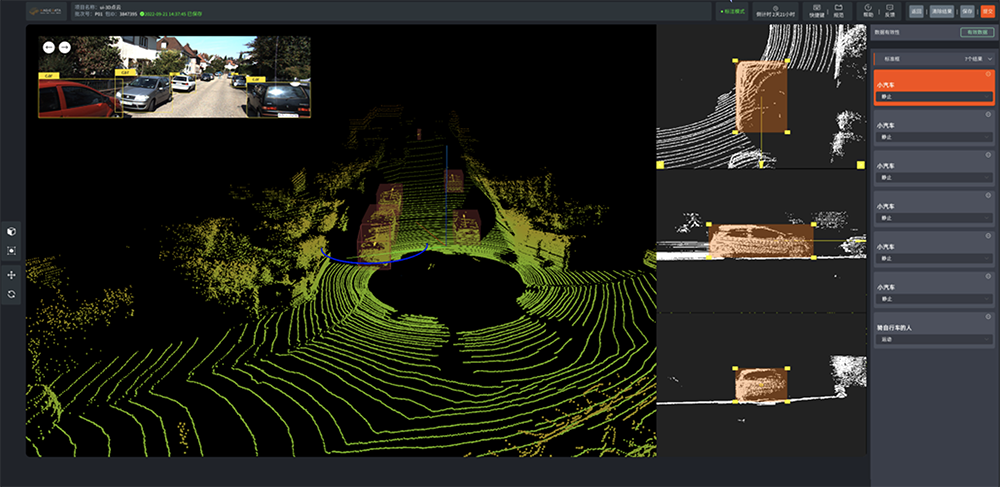
智能化标注平台annotator - 3d点云标注
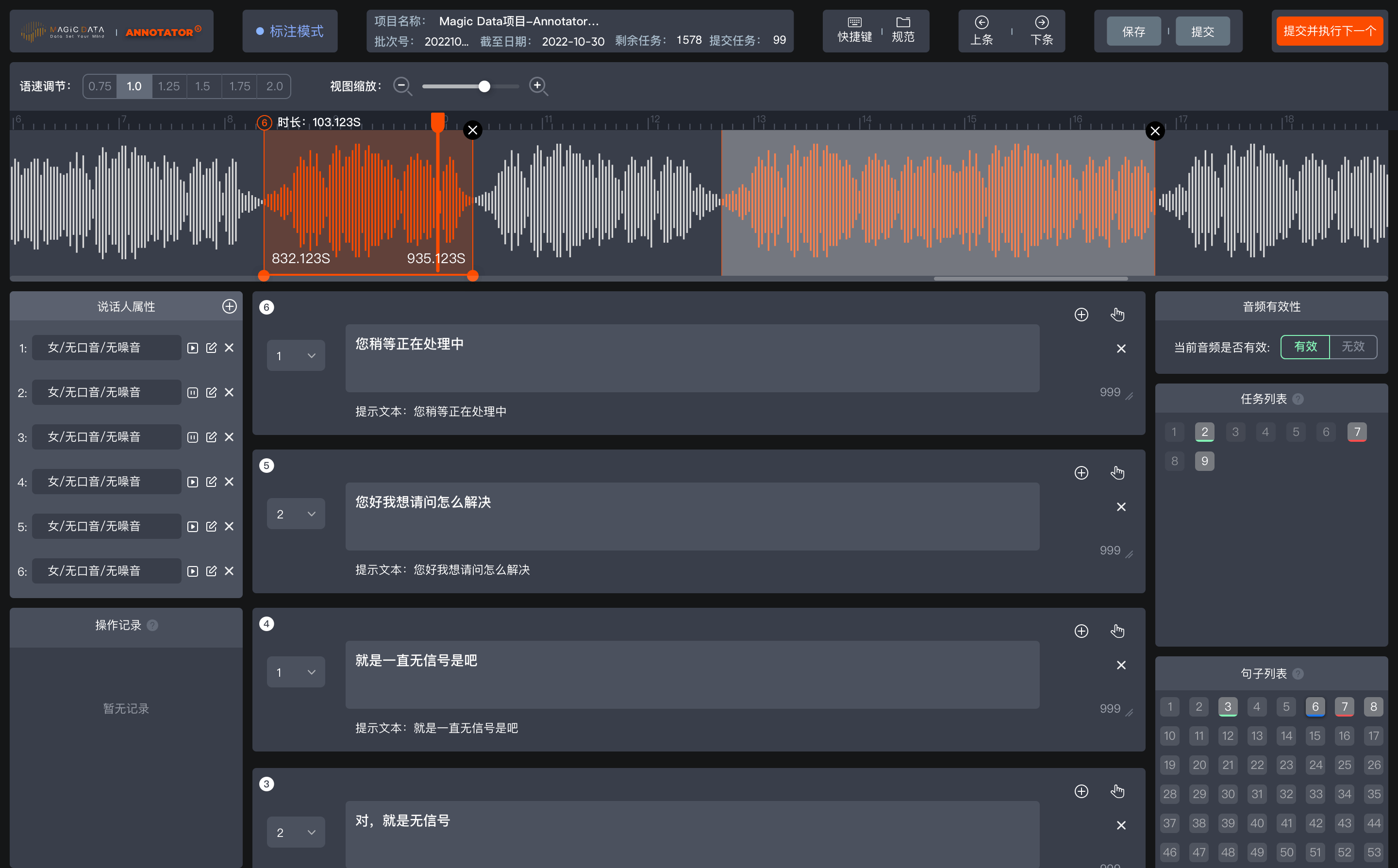
智能化标注平台annotator - 音频标注
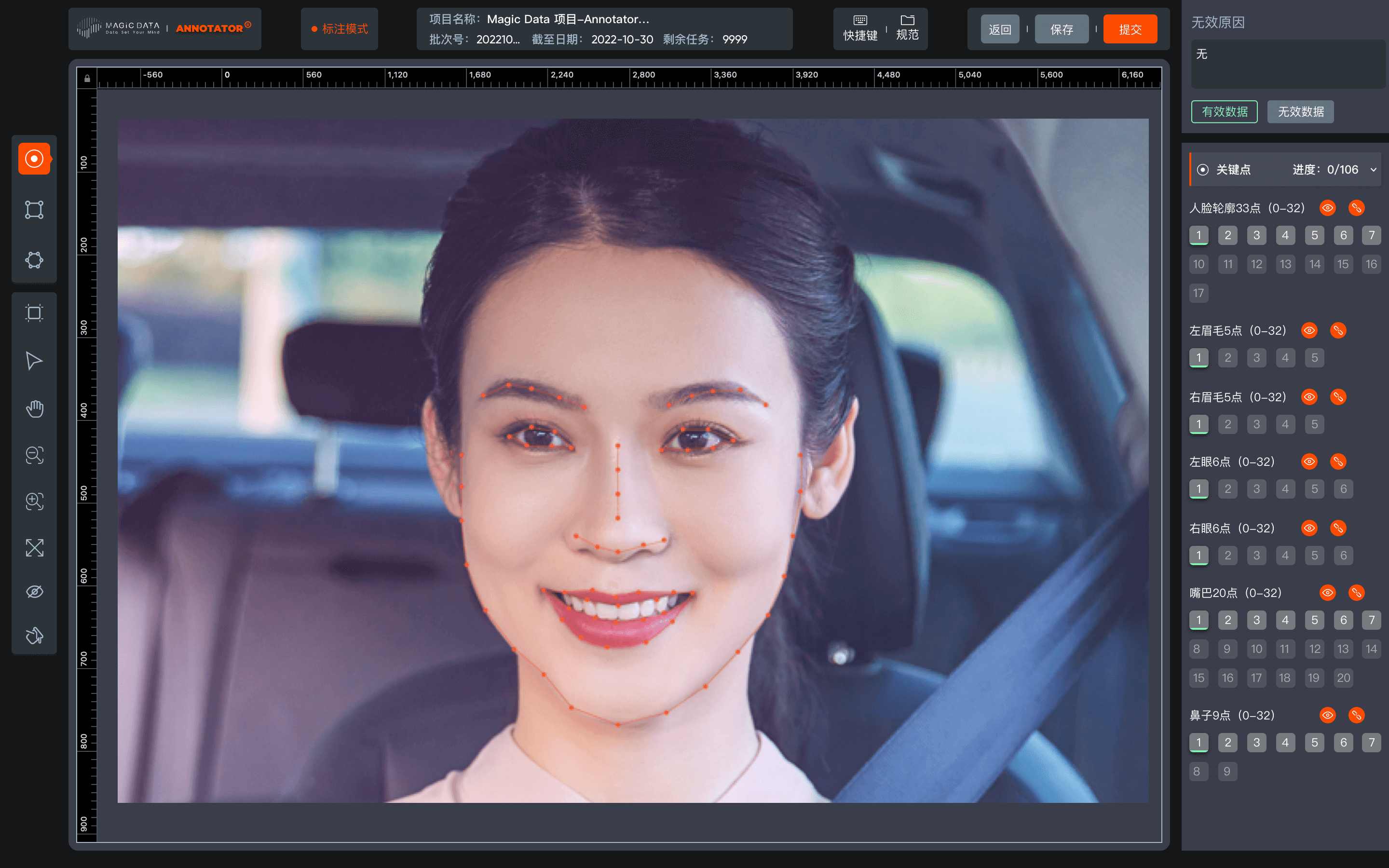
智能化标注平台annotator - 图像标注
了解更多 annotator 智能化标注平台 https://www.magicdatatech.cn/annotator