
发布时间 : 2022-11-24 阅读量 : 496
根据智能化程度的不同,自动驾驶被分为5个等级:l1辅助驾驶、l2部分自动驾驶、l3有条件自动驾驶、l4高度自动驾驶、l5完全自动驾驶,即真正的无人驾驶。
日渐活跃于公众视野的“无人驾驶”概念,往往是指l3及以上级别的自动驾驶。目前l4的试点属于高度自动驾驶。那么无人驾驶是如何实现这些功能的呢?
无人驾驶的核心技术体系主要可分为感知、决策、执行三个层面。
感知系统 相当于人的眼睛、耳朵、负责感知周围的环境,并进行环境信息与车内信息的采集与处理,主要包括车载摄像头、激光雷达、毫米波雷达、超声波雷达等技术。
决策系统 相当于人的大脑,负责数据整合、路径规划、导航和判断决策,主要包括高精地图、车联网等核心技术。
执行系统 相当于人的小脑和四肢,负责汽车的加速、刹车和转向等驾驶动作,主要包括线控底盘等核心技术。
其中无人驾驶的视觉感知系统都基于神经网络的深度学习视觉技术,应用于无人驾驶领域,主要分为四个模块:动态物体检测(dod:dynamic object detection)、通行空间(fs:free space)、车道线检测(ld:lane detection)、静态物体检测(sod:static object detection)。
动态物体检测的目的是对车辆(轿车、卡车、电动车、自行车)、行人等动态物体的识别。
检测的难点包括 检测类别多、多目标追踪、测距精度;外界环境因素复杂,遮挡情况多,朝向不一;行人、车辆类型种类众多,难以覆盖,容易误检;加入追踪、行人身份切换等众多挑战。

空间检测是对车辆行驶的安全边界(可行驶区域)进行划分,主要针对车辆、普通路边沿、侧石边沿、没有障碍物可见的边界、未知边界等进行划分。
检测的难点包括 复杂环境场景时,边界形状复杂多样,导致泛化难度较大。
不同于其它有明确的单一的检测类型的检测(如车辆、行人、交通灯),通行空间需要准确划分行驶安全区域,以及对影响车辆前行的障碍物边界。但是在车辆加减速、路面颠簸、上下坡道时,会导致相机俯仰角发生变化,原有的相机标定参数不再准确,投影到世界坐标系后会出现较大的测距误差,通行空间边界会出现收缩或开放等问题。
通行空间更多考虑的是边缘处,所以边缘处的毛刺、抖动需要进行滤波处理,使边缘处更平滑。而障碍物的侧面边界点易被错误投影到世界坐[标系,导致前车隔壁可通行的车道被认定为不可通行区域,所以边界点的取点策略和后处理较为困难。
车道检测的目的是对各类车道线(单侧/双侧车道线、实线、虚线、双线)进行检测,还包括线型的颜色(白色/黄色/蓝色)以及特殊的车道线(汇流线、减速线等)等进行检测。
车道检测的难点包括 线型种类多,不规则路面检测难度大。如遇地面积水、无效标识、修补路面、阴影情况下,车道线易被误检、漏检。上下坡、颠簸路面、车辆启停时,容易拟合出梯形、倒梯形的车道线。弯曲的车道线、远端的车道线、环岛的车道线等情况的拟合难度较大,检测结果易模糊不清。

静态物体检测是对交通红绿灯、交通标志等静态物体的检测识别。
检测的难点包括 红绿灯、交通标识属于小物体检测,在图像中所占的像素比极少,尤其远距离的路口,识别难度更大。
在强光照的情况下,有时人眼都难以辨别,而停在路口的斑马线前的汽车,需要对红绿灯进行正确的识别才能做下一步的判断。交通标识种类众多,采集到的数据易出现数量不均匀的情况,导致检测模型训练不完善。交通灯易受光照的影响,在不同光照条件下颜色难以区分(红灯与黄灯)。且在夜晚中,红灯与路灯、商店的灯颜色相近,易造成误检。

深度学习模型离不开数据的加持,缺乏大量的无人驾驶的数据是阻碍视觉感知系统在自动驾驶领域应用的主要原因之一,而现有的数据集无论是在数据量,还是采集环境上都与实际需求相差甚远。
magic data作为全球领先的ai数据凯发体育网的解决方案提供商,能够专业有效的针对具体需求,通过智能化标注平台annotator构建规模化的无人驾驶数据库。通过基于真实场景下的数据,推动计算机视觉和机器算法在自动驾驶领域的发展。
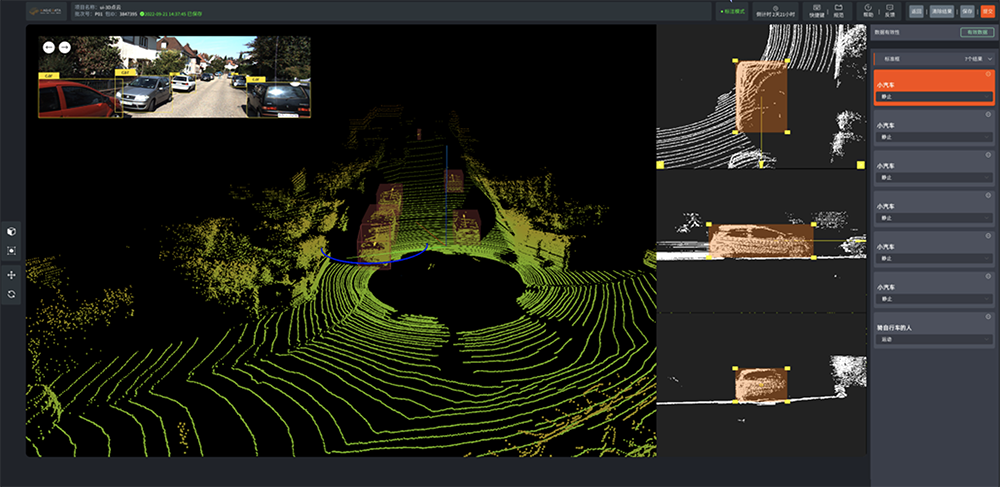
annotator智能化标注平台 3d点云标注
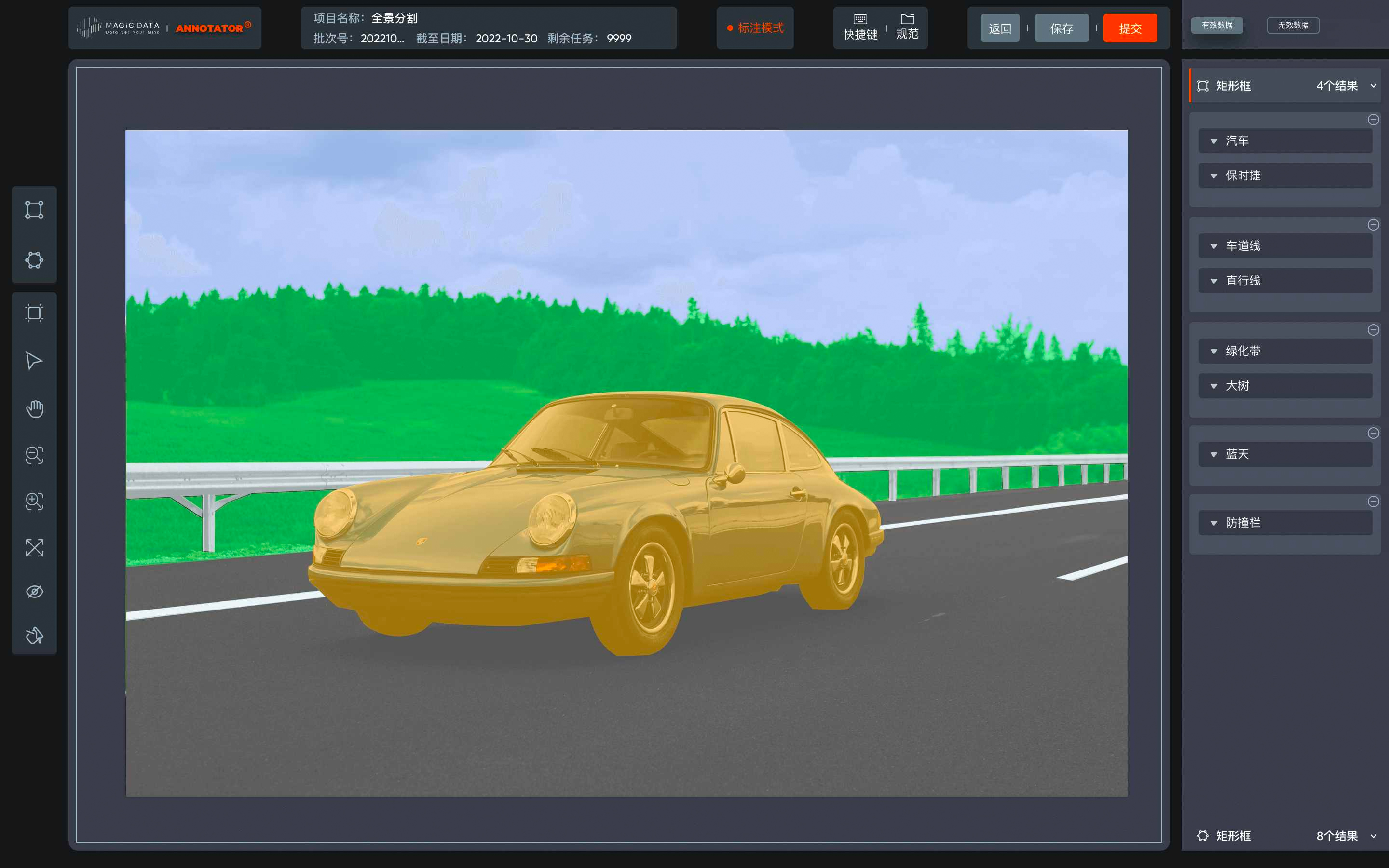
annotator智能化标注平台 图像标注
了解更多智慧出行ai数据凯发体育网的解决方案